



CONTACT
お問い合わせ
この記事についてのご質問など、お気軽にお問い合わせください。
お問い合わせはこちら
![]()


ChatGPTをはじめとする生成AIの進化がめざましい中で、いかにして自社独自の知見や最新情報を業務に活かすか——この問いはいま多くの日本企業で喫緊の経営課題となっています。しかし、ただAIツールを導入すれば効果が出る時代は、終わりを迎えようとしています。というのも、汎用性が高い生成AIであっても、「自社文書を根拠にした精緻な回答」「アップデート頻度の高い最新ナレッジへの対応」「誤情報の排除」といった本質的な課題は、従来の仕組みでは十分に解決できないためです。
こうしたジレンマに真正面から向き合う手段として、近年急速に注目を集めているのが「RAG」(Retrieval-Augmented Generation=検索拡張生成)です。RAGは検索技術と生成AIを融合することで、「自社独自データを根拠としながら、自然言語で高品質な応答を返す」という理想を現実に近づけました。世界中の企業がその可能性を探り、日本でも先進的な導入が広がりつつあります。
本記事では、RAGとは何か、その強みや限界、具体的なユースケースから導入時のベストプラクティス、よくある課題までをビジネス視点で徹底解説します。単なる技術紹介を超え、現場で実際に成果を出すための指針まで網羅していますので、「RAGについて知りたい」「今後AIを使った業務改革を進めたい」とお考えの皆さまにとっても必ずや有益なはずです。では、RAG時代の扉をともに開いていきましょう。
RAG(Retrieval-Augmented Generation、検索拡張生成)とは、従来の生成AIの枠組みを飛び越え、AIが「自分で探し、見つけた根拠を元に、信頼性の高い回答を導き出す」ための革新的アーキテクチャです。もともと大規模言語モデル(LLM)は膨大なデータで事前学習されているものの、その知識は学習時点で固定され、新たな動向や社内独自のデータには疎いという根本的な限界がありました。これはとくに法務や技術系の分野、日々更新されるルールが重要となる現場において、重大な障壁となっていました。
こうした問題意識から誕生したRAGは、「回答生成の都度、関連情報を外部の知識ベースから検索し、回答根拠を組み込む」仕組みで、AI応答の質を根本から引き上げます。LLM単体時代の「もっともらしい誤情報=ハルシネーション」課題にも有効に機能するため、信頼性を重視する日本企業の現場から高く評価されているのです。
RAGは、社外で一般公開されていない自社内の専門マニュアルや規程、顧客とのやりとり記録、そして日々更新されるFAQなど、多岐にわたるナレッジ資産をフル活用できる点で、単なるAIツールとは根本的に異なる価値を持っています。現場業務に即した、根拠のある解答が得られるという点は、意思決定の質を飛躍的に向上させるとともに、DXを加速させる「AI民主化」の強力な推進力ともなっています。
RAGは「根拠のあるAI回答」を自動的に生成し、企業におけるAI活用の最大の障壁を突破する技術として、今や世界的な潮流となりつつあります。
背景には、従来の生成AIの課題を打破するための世界的な動きや、国内外の多くの企業でのRAG実践事例が積み重なっていることも見逃せません。
RAGの定義を押さえた上で、「実際にどのように働くのか?」と疑問を持つ方も多いのではないでしょうか。ここでは、例え話や日常的なシーンも交えて、直感的にRAGの動きを掴んでいきます。RAGを一言で言えば、「優れた図書館司書と凄腕の解説者のチームワーク」といえるでしょう。
例えば、「新しい経費精算規程の、出張時に必要な手続きと注意点を知りたい」と質問したと想像してください。従来のLLMなら、学習済み知識のみで推論し、「たぶん」こうだろう、という形で解答が出力される可能性があります。これに対してRAGは、まず「どの資料に載っているか」を検索(Retrieval)し、関連する規程・通達のドキュメント断片(チャンク)を素早くセレクト。次に、その情報をもとに「出張申請書の提出と承認、領収書の処理、規定金額の厳守が必要です」など、的確かつ業務に即した形で要約し、自然な文体で生成(Generation)して答えてくれます。
この働きは、まるで図書館の司書が「この本・このファイルが参考になりますよ」と指し示し、その道の専門家が「要点はここです」とわかりやすく噛み砕いてくれるようなもの。ユーザーは信頼できる社内ナレッジに根差した、文脈に合った回答を受け取れる──そんなイメージを持つと、RAGの本質がより身近に感じてもらえるかもしれません。
このようなRAGのユースケースは、業務の情報検索の最適化や、実際にさまざまな業種で実用化が進む理由につながっています。
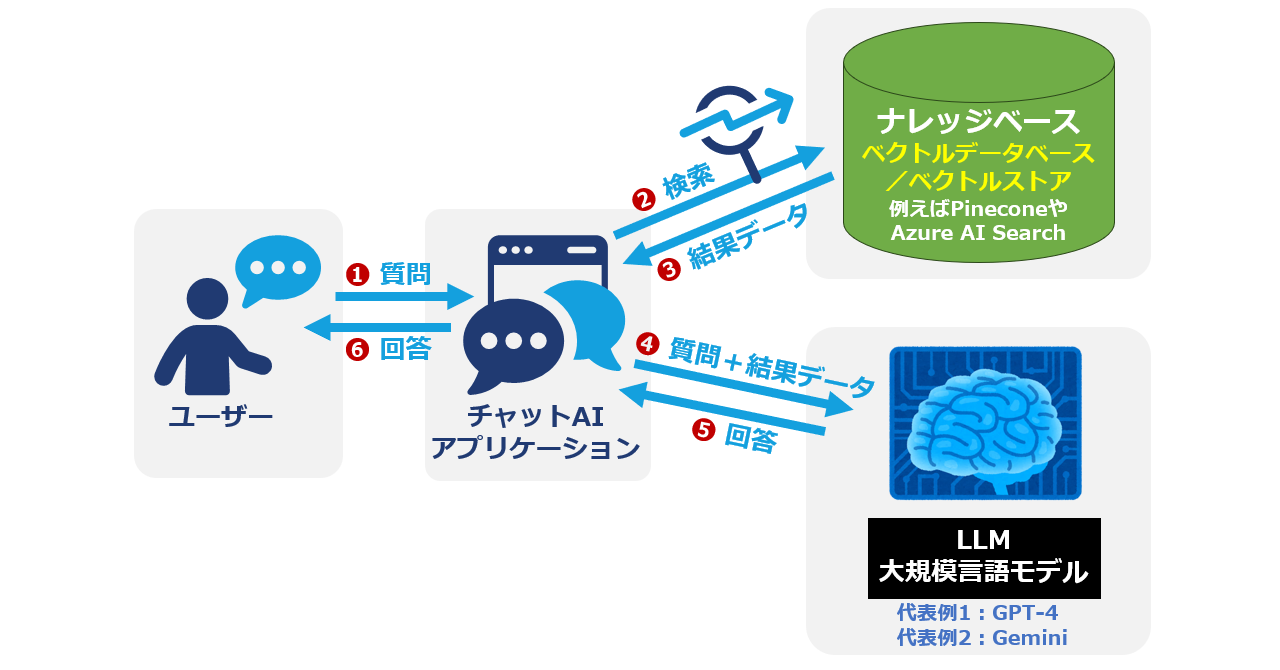
ここからは、RAGがどのような技術で動いているのか、その中身を見ていきましょう。RAGシステムは大きく「データ準備段階」と「回答生成段階」の2フェーズで構成されます。まず、インプットとなる社内ドキュメントやFAQ、仕様書、議事録など多様な情報ソースを集約し、それらをAIが理解しやすい単位(チャンク)に分割。「いつ作成されたか」「誰が責任者か」などに関するメタデータを付けたうえで、不要な文字列や重複も事前に除去します。
テキスト化・チャンク化された各断片は、埋め込みモデルと呼ばれるAIにより「意味ベクトル」へと数値変換されます。この際、文章の微妙なニュアンスやコンテキストも加味した上で、多次元空間上に配置されるため、単純なキーワード一致では発見できない類似性も抽出できます。このベクトルデータを高速に検索・管理するのが、FAISSやMilvus、Pineconeなどの「ベクトルデータベース」です。
ユーザーから質問が投げかけられると、その質問文も同じくベクトル化され、「どのチャンクが最も意味的に近いか」を計算し、複数件を抽出します。その抽出結果(=根拠ドキュメント)をプロンプト文に組み込み、LLMへ渡します。このとき、「出典を明記」「参照情報のみで応答」「分からない場合はその旨を明確に」など、応答指示も含められます。LLMは渡された情報に基づき、AIならではの自然な日本語で、かつ論理性のある回答を返します。
この流れを図式化すれば、「ドキュメント前処理→意味ベクトル化→ベクトルDBで検索→根拠情報+ユーザークエリのプロンプト生成→LLMによる応答」という一連のデータパスになります。実際にはクラウド上にインフラを構築したり、クエリ応答パフォーマンス(レイテンシ)やコスト最適化も考慮しながら運用することが多いです。
RAGと従来型の生成AI(LLM単体)で最大の違いは、「知識の元となる情報の扱い方」です。LLM単体では、大規模コーパスを用いて事前学習した知識の範囲内から答えを生み出します。つまり「モデルの中にしか情報ソースがない」状態。一方、RAGでは、「毎回最新の外部情報や、社内の限定情報にアクセスしてから答えを作る」ことが最大の特長です。
この違いが実際のビジネスにどんな影響を与えるか。まず「情報の鮮度」(最新性)。LLM単体では、学習時点より後のデータや、限定的な社内文書には全く対応できません。しかしRAGなら参照する知識ベース(インデックス)を更新すれば、すぐに反映可能となり、「世の中の変化」や「自社運用ルールの新旧」も柔軟にカバーできます。
また、根拠の明示(Explainability)と誤回答リスク(ハルシネーション)の低減という点でも違いが際立ちます。RAGは「この根拠ドキュメントに基づき回答を生成」とAIに明示的な指示ができるため、「情報の出所が分からない」「あとで確認したら違っていた」という危険を大幅に抑えられます。法的な責任や、顧客対応の品質がシビアに問われる現場では、この信頼性の高さが特に重要といえるでしょう。
もっとも導入の簡便さを優先するならLLM単体も魅力です。APIの呼び出しだけで成果物を素早く生み出せる一方、RAGは「何を根拠情報とするか」「そのデータをどのように管理、更新するか」といった準備が不可欠。ですが、逆にこの点をしっかり設計できれば、RAG導入による業務品質の向上と差別化は、他のどんなAI活用にも勝る武器となりえます。
RAGは「根拠に基づく安全なAI回答」を求める業務(カスタマーサポート・社内QA・法務相談など)で強力な解決手段になることが多いです。
より詳細な比較や選定の考え方については、RAGと生成AIの違い解説もご参照ください。
RAGの活用シーンは多岐にわたります。中でも注目度が高く、かつ具体的な成果が出ているのが「カスタマーサポートの自動化」と「社内ナレッジ共有の最適化」です。たとえば、FAQや製品ドキュメントをRAGの知識ベースとして構築し、チャットボットを通じて顧客の質問に対し「24時間根拠付きで正確に」回答できるようになれば、対応品質の標準化・一次解決率の向上・工数の大幅削減が期待できます。
また、これまでは「誰がどんな情報を持っているか」が属人的だった社内の知識共有においても、RAGによる一元化・横断検索が大きな効果を発揮します。「最新マニュアルがどれか分からない」「重大な決定の背景が探せない」などの悩みも減り、業務効率と新入社員のオンボーディングも加速します。まさに人とAIの最適な協働環境が醸成されるのです。
他にも専門性が高い法務・コンプライアンス分野や、複雑な商品提案・案件管理を必要とする営業、テクニカルサポート分野での活用も拡大中です。「この契約書のリスク要因を洗い出して」「類似事故の過去事例を挙げて」「この製品に関する最新ガイドラインを参照した上で説明して」——こうしたリクエストにスピーディーかつ根拠を伴って応えられるのは、RAGという新しい業務基盤ならではの強みです。
実際に、国内外の企業の導入事例や、業界ごとのユースケースについても多くの報告が蓄積されています。「RAGの活用可能性はほぼ無限」といっても過言ではありません。
導入を検討したら、まずはPoC(概念実証)による小規模な実装から始めるのが鉄則です。第一歩となるのは「知識ベースに何を載せるか」の棚卸し。必須文書を整理、クレンジングし、必要に応じて機密レベルのタグやバージョン管理も整えます。続いて、埋め込みモデル(テキストのベクトル変換方式)やベクトルDB(FAISS、Qdrant、Pinecone等)の選択、更新ポリシーの設計を進めます。
「プロンプト設計」も極めて重要です。「与えられた資料だけを根拠に」「不明点は不明と表明」などの条件を分かりやすく記述し、ハルシネーションを抑制します。並行して「応答の品質評価指標」も設計しましょう。具体的には正答率・根拠提示率・レイテンシ・運用コスト(トークン消費量やAPI代金)などが重要KPIになります。指標ごとに業務現場とすり合わせることで、導入効果を後から定量的に判定できます。
PoCのなかで「誤情報」「知識ベースの抜け漏れ」「遅延」など課題が見えた場合は、すぐにデータ追加・索引再構築・モデル選択の見直しを行います。本番展開の際はアクセス権管理やセキュリティ措置も忘れず強化し、クラウドかオンプレミスかも要件に応じて選びましょう。部分展開から段階的に全社導入…という漸進的な進め方が、RAGプロジェクトの成功率を高めます。
「完璧を目指さず、まずは小さく始めて磨きながら広げる」——AI時代のプロジェクト推進に求められる姿勢です。
RAG導入ベストプラクティスも参考に、段階的な改善を重ねることが重要です。
どんなに優れた技術にも運用上の落とし穴は存在します。RAG導入・運用でよく挙がる課題とその対策も解説しましょう。まず「インデックスの肥大化・古い情報との混在」です。日々アップデートが繰り返される現場では、不要な旧規程や陳腐化したマニュアルが知識ベースに溜まりがちです。これを避けるには、文書ごとにバージョン・有効期限・アーカイブ管理を徹底し、定期的な棚卸をワークフローに組み込むことが不可欠です。
二つ目はセキュリティ。「個人情報や機密事項がうっかりAI回答に混入した」事態は絶対に避けなければなりません。自動マスキングやアクセス権設定付きインデックス構築、多段階のレビュー&承認プロセスによって、情報漏えいリスクを最小限に抑える体制づくりが重要です。特に高セキュリティ要件の現場では、クラウド型ではなくオンプレミス環境での運用も選択肢となります。
三つ目がハルシネーションの完全抑制難易度です。RAGは明らかに誤情報生成を減らせますが、ゼロにはできません。「信頼度が一定値を下回れば『分かりません』と回答」「複数根拠を参照し再ランキング」「プロンプト内で『推測や創作を避ける』と明示」といった工夫を複合的に組み込む必要があります。加えて、データ品質とバイアス問題にも注意が必要です。特定部門だけの情報が多いと偏りや抜け漏れリスクが高まります。多様な部門からのデータ提供とレビュー体制が、AI応答の質そのものを左右します。
RAG導入時は「技術」だけでなく「運用・データ管理体制」も含めた全体最適がポイントです。
これら課題と対策は、RAG運用の現場知見や、課題別の技術的アプローチでも詳しく報告されています。
ここまで、RAGとは何か、仕組みから活用法、課題対策まで体系的に解説してきました。RAGは、単に「AIツールを入れる」という発想を超え、企業が持つ独自情報資産の価値とAIの言語能力を化学反応させるテクノロジーです。今後ますます重要度が増していく仕組みといえるでしょう。
RAGがフィットする業務例を改めて整理すれば――
導入へ進めるなら、まずはPoC(小規模概念実証)から安全に踏み出しましょう。検証すべきKPIは、正答率や満足度(CSAT)・応答速度・対応工数削減効果・トークンコストなど実業務に直結するものが肝要です。継続的なデータ品質管理と、多部門横断型の運用体制を構築することが、RAGプロジェクト成功の最大のポイントです。
RAG導入ノウハウや
最新事例も随時参考にしながら、次世代の業務基盤づくりをぜひ進めてください。
この記事についてのご質問など、お気軽にお問い合わせください。
お問い合わせはこちら